Yaşar Tonta, "Bilgi erişim sorunları ve Internet" Ed. Ali Can,
M. tayfun Gülle, Oya Gürdal ve Erol Yılmaz. Kütüphanecilikte Yeni
Gelişmeler, Kavramlar, Olgular... 37. Kütüphane Haftası Bildirileri. 26
Mart - 01 Nisan 2001 içinde (52-62) Ankara: TKD, 2002.
Bilgi Erişim
Sorunları ve İnternet*
Doç. Dr. Yaşar Tonta
H.Ü.
Kütüphanecilik Bölümü
06532
Beytepe, Ankara
Benden önceki çok
değerli
konuşmacılar gerek ulusal düzeyde, gerekse internet kullanıcıları düzeyinde
değişik yönlerden bilgi erişim sorunlarına değindiler. Ben sizin bildiğiniz
konuları biraz daha es geçerek belki de daha genel bazı sorular sormak
istiyorum. Dolayısıyla da sunuşum spesifik, özellikle elektronik bilgi erişim
sorunları konusundaki spesifik bazı noktaları içermeyecek.
Hızlı Bilgi Artışı
Bilgi artışıyla karşı
karşıyayız. Bir karşılaştırma yapmak için ben size birkaç rakam vereceğim.
Örneğin, kütüphane dermeleri her 14 yılda bir ikiye katlanırken, internette bu
oran, yılda %300 civarında büyümeye karşılık geliyor. Bazı rakamlar
karşılaştırma için; doğrudan erişilebilen yüzeysel denilen web'de 2.3 milyar
belge var. Her gün bu sayıya 7.3 milyon yeni belge daha ekleniyor. Öte yandan
daha derin web'i dikkate aldığımızda, yani web'e bağlı veri tabanları, ancak
doğrudan erişilemeyen, intranet üzerindeki belgeleri, dinamik, hemen siz
kullandığınız anda yaratılanları da düşünecek olursanız, 550 milyar belge
olduğu tahmin ediliyor internet üzerinde.[1]
Bu da her nüfusa 90 belge anlamına geliyor ve bu belgelerin büyük bir çoğunluğu da kamuya açık. Bu rakamlarla
örneğin, en büyük olarak bildiğiniz bir kütüphanenin, Kongre Kütüphanesinin,
içindekileri -ki 170 milyon civarında-
bir karşılaştırın. Tabii bu, bu yıl yapılan bir projeksiyon. Halbuki
daha bundan üç yıl önce 100 milyon civarındaydı internet üzerindeki belge
sayısı ve 10 yıl içerisinde de 800
milyona ulaşacağı varsayılıyordu. Burada kimi hesaplamalara göre 2.3 milyardan, kimilerine göre de 550
milyardan söz ediyoruz.
Bu tür
konuşmaları geç hazırlamanın belki bir avantajı olsa gerek, The Economist dergisinin 26 Mart 2001
tarihli kopyasında dünya üzerindeki bilgi miktarını ölçmeye çalışan iki
profesörün yaptığı çalışmayla ilgili bir yazı yayımlandı.[2]
Gördüğünüz logaritmik ölçekli bir tablo (bkz. Şekil 1). Burada toplam bilgi
miktarı, 2.120.000 terabyte, aşağı yukarı 2 exabyte'a karşılık geliyor. Bu
bilgiler hangi şekillerde diyecek olursanız, örneğin çok küçük bir kısmı müzik
CD'leri, DVD'ler, veri CD'leri biçiminde, önemli sayılabilecek bir kısmı
kitaplar, süreli yayınlar, gazeteler ve ofislerde yaratılan dokümanlar
üzerinde, uzun metrajlı sinema filmleri, hastanelerde çekilen filmler epeyce
yer tutuyor. Örneğin, 2 milyar röntgen filmi çekiliyor senede sadece ABD'de ve
ABD Ticaret Bakanlığı'nın verdiği verilere göre de 80 milyar kişisel resim
çekiliyor. Tabii ben burada bilgiyi çok geniş anlamda kullandığım için bu
rakamları veriyorum. Her gün 610 milyar
elektronik posta gönderildiği
hesaplanıyor. 15 trilyon sayfa yazıcı çıktısı
alınıyor ABD'de sadece. Dolayısıyla burada logaritmik ölçeği de dikkate alarak
gidecek olursanız, şu anda en önemli kısmı verilerin, gördüğünüz gibi
manyetik-optik ortamlarda. Bunlar da
ticari kuruluşların sunucularındaki, çekilen video filmlerindeki, kendi
bilgisayarlarımızda disk sürücüleri üzerindeki bilgiler.[3]
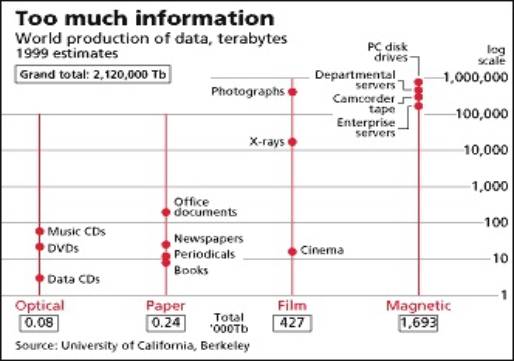
Şekil 1. Dünyadaki veri üretimi (1999).
Kaynak:
Peter Lyman, and Hal Varian, "How
Much Information?" 2000. Çevrimiçi. Elektronik adres: http://www.sims.berkeley.edu/research/projects/how-much-info/charts/charts.html. 10 Aralık 2001.
Tabii ki burada
şöyle bir şey göze çarpıyor: Bilginin büyük oranda demokratikleşmesi ile karşı
karşıyayız ve bu bilgilerin büyük bir kısmının da dijital ortamda olması bu
değişimi kolaylaştıran bir etmen aynı zamanda. Ama bütün bunların ötesinde bu
kadar bilgi fazlalığı, aynı zamanda bir bilgi yüklemesine yol açıyor.
Dolayısıyla da çağımızda bilgi yönetimi
konusu en sıcak konulardan bir tanesi haline gelmiş durumda. Bu bilgi
yönetimini, ister kişisel düzeyde düşünün, ister örgütsel düzeyde, isterse
toplumsal düzeyde düşünün. Dolayısıyla da belki de okur yazarlıktan bir sonraki
aşama, Alvin Toffler'ın da dediği gibi aslında bilgiyi nasıl bulabileceğimizi
öğrenme. "Geleceğin cahili okuma yazma bilmeyen değil de, bilgiye nasıl
erişileceğini bilmeyendir" diyor Alvin Toffler.[4]
Bilgi Depolama
Madem ki bu kadar
büyük ölçeklerdeki verilerden söz ediyoruz, birazcık tarihsel olarak geriye
giderek, bilgi depolama ortamlarına değinmek istiyorum. Elbette en başta gelen
bilgi depolama ortamı insan beyni. Tabii ki hemen arkasından da yazı vs.
geldiği için, insanlar kendi beyinleri dışındaki ortamlarda da bilgi
saklayabilme imkânını kazanıyorlar. Ama yazıya karşı çıkanlar da olmuş.
Örneğin, ünlü düşünür Plato, Phaidros adlı eserinde yazıyı bulan Mısır
tanrılarından Theuth ile Mısır Kralı Thamus arasında geçen bir konuşmayı
aktarır. Kral Thamus, Theuth’un geometri, astronomi, tavla oyunu ve zarlar
konusundaki buluşlarına hayrandır. Theuth o zamana kadarki en büyük buluşu olan
yazıyı Kral Thamus'a "Ey Kıral,…işte bir bilgi ki bunun sayesinde
Mısırlılar daha bilgili ve geçmişi hatırlamaya daha yetili olacaklar. Bilginin
de, belleğin de ilâcını buldum!" sözleriyle sunar. Kral Thamus ise yazıyı
onaylamaz ve yazı sanatının kullarına öğretilmesini şu sözlerle reddeder:
'Ey eli hünerli Theuth! Bu dünyada kiminin elinden sanat
yaratmak gelir, kiminin elinden de bu sanatın onu kullanacaklara fayda mı,
zarar mı getireceğini kestirmek. Harflerin babası olan sen, kendilerine
duyduğun sevgi dolayısiyle, verecekleri neticenin tam aksi bir neticeyi
onlardan bekliyorsun. Harfleri öğrenenler, artık belleklerini işletmeyecekleri
için, unutkan olacaklar: işte bu bilgiyi elde etmenin sonu! Yazıya güvendikleri
için, etraflarındaki şeyleri içerden kendi kendilerine hatırlayacakları yerde,
dışardan, kargacık burgacık izler sayesinde hatırlamaya çalışacaklar. O halde
sen bellek için değil, hatırlama için bir ilâç buldun.
Öğrenime gelince; sen öğrencilerine ancak gerçeğe benzer şeyleri öğretirsin,
gerçeğin kendini değil. Bunlar, senin harflerin sayesinde, öğretmensiz olarak
gırtlaklarına kadar bilgiye gömüldüler mi, çoğu zaman hiç bir şeyi doğru dürüst
düşünemedikleri halde kendilerini bilgin sanacaklardır. Sonra, gerçekten
bilgili adam değil de bilgili adam bozması oldukları için çekilmez bir şey
olacaklardır!'[5]
Ancak
insanlarla diğer varlıkları birbirinden ayıran en önemli etmenlerden bir
tanesi, aslına bakılırsa, bu kültürel
akümülasyon olarak nitelendirebileceğimiz insan beyni dışındaki ortamlarda
bilgi saklayabilme özelliğimizdir. Yani ne
iki ayak üzerinde yürümemiz, ne dil özelliğimiz, ne şu ne bu bizi
hayvanlardan ve diğer varlıklardan ayırıyor, ama sadece kültürel birikim bizi
diğer varlıklardan ayırıyor. Yani, bizim ürettiğimiz teknolojik ürünlerde,
bizim bulduğumuz kâğıt, bilgisayar vs. üzerinde bilgi saklayabilmemizdir
kültürel birikim. Bu, bizi diğer varlıklardan ayıran en önemli özellik, başka
hiçbir şey değil.
Dolayısıyla da dış ortamlarda, insan beyni dışındaki ortamlarda bilgi saklamaya başladıktan sonra, kuşkusuz durum çok daha değişti. Hatta, Karl Popper'di sanıyorum, "Dünya uygarlığı bir savaşla yok olup, geriye kütüphanelerde saklanan nesnel bilgi içeriği kalırsa, uygarlığı yeniden kurmak mümkündür. Halbuki bu nesnel bilgi içeriği, yani kütüphaneler yok olup, yalnızca öznelerin öğrenme yeteneği kalsa, çağdaş uygarlığı yeniden inşa etmek hemen hemen imkânsızdır" diyor.[6]
Dolayısıyla bu manyetik, optik depolama
aygıtları, dağıtık depolama kolaylıkları, bize gerçekten de bu tür
bilgileri, günlük karar alma
sürecimizin bir parçası haline
getirmede kolaylık sağlıyor. Tabii ki
hâlâ bu dış ortamlara rağmen, biz henüz depolama kapasitesi açısından
insan beynine yaklaşan bir makine üretmiş değiliz. Bunun için öngörülen tarih
2019. Kurzweil'in The Age of Spiritual Machines diye bir kitabı var, orada verilen
tarih bu.[7]
Yani daha yaklaşık bir 20 yıl bu güce erişecek bir şey belki de olamayacak,
belki de daha kısa sürede olacak.
Bilgi İletim ve Bilgi İşleme
Değinmek istediğim ikinci
nokta, bilgi iletim ortamlarındaki hızlı gelişmeler. Burada da elbette hemen
aklımıza bilgisayar ağları geliyor. Daha bundan iki yıl önce Nortel saniyede
1.6 trilyon bit'lik bilgi aktarma
kapasitesine erişmişti. Bu belki bir çoğumuz için fazla bir anlam ifade
etmeyebilir. Şu anda Kongre Kütüphanesi'nin sahip olduğu bütün basılı ya da
kaydedilmiş ne varsa, 14 saniyede bir yerden bir yere aktarılması anlamına
geliyor bu kapasite.[8] Dolayısıyla da çok büyük kapasitelere, bilgi
iletme açısından da erişmiş durumdayız.
Bir de bilgi
işleme ortamlarına bakalım. Burada da yine karşımıza öncelikle insan beyni
çıkıyor bilgi işleme açısından. Biliyorsunuz, bundan 4-5 yıl önce insan
düşünürken nöronlar arasında ne olduğunu, yani nöronlar arasındaki enerji
akışını resmedip bir bilim dergisinin kapağına koymuşlardı. Henüz bilgi işleme
açısından da bilgisayarlar, insan beynine yetişebilmiş durumda değil. Ama yine
biraz önce sözünü ettiğim Kurzweil'in kitabında, insanlardan daha akıllı
makineler yaratılacağı yazılı. Yine de, insan beyni gibi bilgi işleyen
makinelerin ortaya çıkması için 2030’lara dek beklenmesi gerektiğini söylüyor
Kurzweil. Tabii, bu arada çok ilginç diğer bir gelişme olarak, "yapay
beyin"den söz ediliyor. Yani şu anda nasıl ki takma bacak, takma kol,
takma meme vs. varsa, çok yakın bir zamanda da insanlar herhalde kendi beyin
güçlerini yapay beyinle belki de destekleyebilecek duruma gelecekler. Çok merak
ediyorum tabii ki; yapay beyin taktırmak isteyenler olur mu acaba? Beyin nakli de diğer organ nakilleri kadar
popüler olacak mı? Meme büyütme operasyonları gibi beyin büyütme operasyonları
yapılabilir mi? Olursa en çok kimin beyni "itibar" görecek? O zamanki
estetik cerrahların işleri kolay olmayacak anlaşılan. Bunu göreceğiz sağ
olursak.
Bilgi Erişim İkilemi
Bu gelişmelere rağmen, ben
konuşmamın da esas kısmını oluşturacak
olan, "bilgi krizi" ya da "bilgi erişim sorunu" nedir ona
bir değinmek istiyorum. Şu slaytta gördüğünüz şeyleri çok kısa geçeceğim.
Dediğim gibi benden önceki konuşmacılar kısmen buna değindi. Ağların iletim
gücü fazla, bilgi işleme gücü fazla, kullanıcı arabirimleri giderek gelişiyor
-her ne kadar şu anda kullanıcı arabirimleri hâlâ ham, kaba iseler de. Bu arada
tabii hemen not etmekte de yarar var; kullanıcı ara birimleri son derece hayati
bir önem taşıyor bilgi sistemlerinin kullanılması açısından. Çünkü Mooers
Yasası diye bir yasa var. Bu yasaya göre; "Bilgi edinmek için katlanılan
zahmet, bilgi edinmeden yaşamanın zahmet ve sıkıntılarından daha fazla ise
bilgi erişim sistemleri kullanılmamaya başlar" diyor. Yani siz eğer
kullanımı zor sistemler yaratıyorsanız, o zaman kişi kararını verecek ve
"ben bilgisiz de yaşayabilirim" gibi bir kanıya varabilecektir. Bilgi
profesyonellerinin eğitimi; bugün özellikle yurt dışından gelen konuşmacı, bu konuyla
ilgili belli başlı yönelimleri de özetledi. Kullanıcı eğitimi bunların en
önemlilerinden bir tanesi. Ama
"bilgi erişimin temel ikilemi" diye tanımlayabileceğimiz bir sorun
var. Aydın Köksal hocamız da bundan bir miktar bahsetti. Nedir o temel ikilem:
"Hakkında bilgi bulmak için bilmediğin bir şeyi tanımlama gereği."
Bilgi erişimin temel paradoksu bu. Yani bu, "sözlük" kelimesinin
anlamını bilmeyen bir kişinin içine düşebileceği durumu bize söylüyor. Bu kelimenin anlamını bilmeyen bir kişi bilmediğini
öğrenmek için sözlüğe bakmayı da akıl edemez.[9] Ve, veri
tabanlarından değil de bizim anladığımız anlamda "bilgi erişim"den
söz ettiğimiz zaman, iyi tanımlanmamış, çok fazla ya da çok az bilgiye
erişebileceğimiz durumlardan söz ediyoruz. Yoksa bilgi erişim, "bana adı
Ahmet olan kişinin dosyasını getir", "plaka numarası şu olan arabanın
detaylarını getir" vs. hikayesi değil. Bilgi erişimin profesyonel açıdan
temel ikilemi bu.
Bibliyografik Denetim
Şimdi gelelim bibliyografik
denetim konusuna. Söylemeye gerek yok; yıllar boyunca kaynakçalar, dizinler,
kataloglar vs. yaratmışız Kâtip Çelebi'den bu yana; ve giderek bu konuda daha
iyi yerlere geliyoruz. Ama soruna bir de şu açıdan bakalım: Bütün tarih
boyunca, bütün ülkelerin bütün katalogcuları diyelim ki birleşmişler ve 40 milyon tekil (unique) kitap kataloglamışlar. Sayı üç aşağı beş
yukarı farklı olabilir, benim aldığım rakam bu. Ben size ilk slaytta derin
web'de 550 milyar, yüzey web'de 2.3 milyar belge olduğundan söz ettim. Biz eğer
tarih boyunca 40 milyon tekil kitap kataloglayabilmişsek, belki de, diyelim ki,
onun 10 katı kadar da makale
kataloglamışız, acaba biz çözümü zor olan bir sorunla mı karşı karşıyayız
burada? Yani, internetin kataloglanması bugün "seksi" konulardan bir
tanesi bizim literatürde. Ama acaba neyi neyle çözmeye çalışıyoruz? Ne
yapabiliriz? Artı, bir de internet ortamındaki
belgeler dinamik belgeler. Siz istediğiniz anda oluşturulan belgeler
var. Artı, zamanı dolunca hiç size "çaktırmadan" ortadan kaybolan
belgeler söz konusu. Bu durumda bu belgeleri bir şekilde kontrol edebilecek
miyiz? Ki, yapılan bir araştırmaya göre
bir internet belgesinin ortalama ömrü 44 gündür.[10]
Bunun için önerilen şey metadata,
yani "bilgi hakkında bilgi" terimi. Fakat burada da yine rakamlar hiç
iç açıcı değil. OCLC'nin yürüttüğü ve kütüphanelerin gönüllü olarak katıldığı
ortaklaşa internet kaynaklarını kataloglama projesi (CORC) çerçevesinde,
1996'dan bu zamana kadar entellektüel açıdan kataloglanmış web sayfası sayısı
300 bin civarında. Dolayısıyla, her ne kadar şu anda web sayfalarında
"self servis" kataloglama diyebileceğimiz Dublin Core vb. gibi
kolaylıklar varsa da, sizin yaratacağınız kataloglama bilgilerini buraya
koyabilir iseniz de, yine de buradaki sorunun karşımızda durduğunu söylemekte
yarar var.
Elektronik
kaynakların dizinlenmesiyle ilgili olarak göz önünde bulundurmamız gereken bir
diğer nokta da şu: Basılı kitap ve dergilerde esas bilgiyle (içerik)
kataloglama bilgisi (metadata) birbirinden genellikle ayrı. Çünkü basılı
kitabın/derginin elektronik ortamda tam metni yok. Ama biz onun bir şekilde bir
temsilini yaratıyoruz, 3x5 inç
büyüklüğündeki kataloglarda, katalog bilgisi veriyoruz vs. vs. Şu anda
internet ortamında gördüğümüz şey ise şu: Bilginin kendisi (içerik) metadata
dediğimiz dizin bilgisi ile birlikte geliyor. Yani bilginin kendisini kaybetmek
demek, dizin bilgisini de kaybetmek demek. Halbuki bugün bir kütüphaneden bir
kitabı alır ve kaybederseniz, o kitapla ilgili dünyanın her tarafında bir
şekilde bibliyografik bilgi var, en
azından. O zaman elektronik belgelerin kısa sürede ortadan kalkması - yukarıda
kültürel akümülasyondan söz ettik- bizi acaba nasıl bir gelecekle karşı karşıya
bırakacak? Elektronik
kaynaklarda metadata esas bilgi kaynağıyla birlikte geldiğine göre, bu
kaynakların ömrünün kısa olması nedeniyle kataloglanamadan internetten
kaybolması bu bilgilerin bir daha geri gelmemek üzere kaybolması anlamına mı
geliyor? Çünkü internet üzerindeki elektronik bilgi bir kez gittiği anda bir
daha ne içeriğe ne de dizin bilgisine erişme şansımız var. (Basılı kaynaklar için hiç olmazsa kütüphane
kataloglarında, kaynakçalarda vs. metadata bir şekilde saklanıyordu.) Belki indirme
(downloading) nedeniyle bazılarının bilgisayarlarında bu kaynaklar depolanmış
olabilir. Ama en azından metadata oluşturma işi, yani internetin kataloglanması
işi ciddi olarak önümüzde duruyor.
Biraz önce
elektronik bilginin metadata bilgisiyle birlikte gelmesinden söz etmiştim.
Dizinleme sorununu halletmek için daha güçlü makinelerimiz var; fiziksel olarak
bazı şeyler yapmıyor değiliz. Otomatik dizinleme aracılığıyla dokümanda geçen
her kelimeyi indeksleyebiliyoruz vs. Bunlar bir bakıma yarar da sağlıyor. Bugün
belli başlı arama motorları, bir arama yaptığınızda nereden baksanız 300 milyon
dokümanı arıyor, sizin aradığınız kelime ile ilgiil olarak. İstemediğiniz
konudaki dokümanları pekala filtreleyebiliyorsunuz. Yine böyle çok kaba çalışan
akıllı ajanlar var. Diyorsunuz ki, "Ben bir hafta sonra bilgi erişim
sorunları konusunda bir sunuş yapacağım. Git bir gez bakalım, son zamanlarda bu
konuda yapılan çalabileceğim bir sunuş
var mı? Varsa onlardan 'araklar', bir konuşma metni ortaya
çıkarırım" gibisinden. Fakat bunlar
hâlâ son derece kaba araçlar. Dolayısıyla bu aşamada, her ne kadar biraz önce
verdiğimiz internetin kataloglanmasıyla ilgili rakamlar gözümüzü korkutuyor ise
de, bu kaynaklar üzerine insan beyninin ürünü olan yapıyı bir şekilde empoze
etmemiz gerekiyor. Oysa, arama motoru kullanan herkesin bildiği gibi, otomatik
dizinlemeyle çalışan sistemlerde sap saman çoğu zaman birbirinden
ayırdedilmemiştir.
Burada bir diğer
soru da şu: Acaba her zaman tam metin bilgi tercih edilir mi? Metadata her
zaman asıl bilginin yerini tutar mı? Bunun böyle olmadığını biliyoruz. Mesela
kartografi alanında çalışanlara gidin, bu soruyu sorun bakalım ne diyecekler?
Elbette metadatayla çalışmak zorunda olan disiplinler var. Ama metadatanın,
yani bilgi hakkında bilginin, esas bilginin yerini tutup tutmaması ise bir
başka konu. Eğer öyle olsaydı, renkli yazıcılar aracılığıyla para basan bütün
kalpazanlar herhalde şu anda köşeyi dönmüş olurlardı. Dolayısıyla burada biz
her ne kadar metadata yaratmaya çalışıyor isek de ve çoğu zaman da bu bilgi,
tam metnin kendisinde gömülü ise de bazı durumlar var ki metadata ile yetinebilyoruz, bazı durumlarda da daha ileri
gitmemiz gerekiyor.
Arşivleme
Bilgi erişimle ilgili bir
başka sorun; elektronik bilgilerin depolanması ve arşivlenmesi. Biraz önce de
değindiğim gibi, sonuç olarak elektronik ortamdaki bilgilerin daha az yararsız
olduğunu bugün kimse söyleyemez. Sap saman karışıktır, orası ayrı bir olay. Ama
biraz önce size 26 Mart 2001 tarihli The
Economist dergisinden bir tablo koydum buraya. Acaba elektronik ortamda bu
bilgiye erişmeseydim nasıl yapardım? Tabii ki burada arşivlemeyle ilgili temel
sorun daha da derin. Bu, müzecilerin de sorunu, kütüphanecilerin de, kitap
seçenlerin de. Temel sorun, neyi saklayacağız, neyi atacağız? Yani, arşivci
olarak düşünün, müzeci olarak düşünün, galerici olarak düşünün… Bizim sorunumuz
da bu. Son zamanlarda elektronik kaynakların arşivlenmesiyle ilgili olarak
ortaya çıkan bir görüş kısaca şöyle özetlenebilir: "Elektronik ortamda
depolama nasıl olsa oldukça ucuzlamış durumda. Arşivleme teknolojileri, eski
bir teknolojiden yenisine geçişi çok kolaylaştırmış durumda. O zaman biz niye
her şeyi depolamıyoruz?" Bu, çözüm müdür, değil midir, üzerinde düşünelim.
Çünkü esas amaç, depolamak vs. değil, iş gelip yine erişime dayanıyor. Yani
sizin için önemli olan, o anda karar vermek üzere, hangi işi yapıyorsanız
onunla ilgili bilgi edinmek üzere ihtiyaç duyduğunuz bilgidir. Her şeyi belki
depolayabilirsiniz, ama istediğiniz anda erişebilir misiniz, önemli olan bu. Ki
nitekim şu anda internet üzerindeki taramaları, yangın hortumundan su içmeye
benzetiyorlar. Yani o kadar güçlü geliyor ki istediğinizi almak mümkün değil.
Sonuç
Bu aşamada, bu bilgi
patlamasına internet üzerinde aradığımız bilgiyi bulmak için kullandığımız
dizinleme ve bilgi erişim teknikleri yeterince cevap veremiyor. Biraz önce
arama motorları, otomatik dizinlemeden söz ederken, bunların çok ham, kaba
olduğunu söylemiştim. Oysa biraz önce de söylediğim gibi, beyin dışında kayıtlı
bilgileri, günlük karar alma ve üretim sürecinin bir parçası haline getirmemiz
ve etkin bir biçimde yararlı bilgilere erişmemiz gerekiyor. Bunu yapay beyinle
yaparsınız, akıllı ajan kullanırsınız, vs. Önemli olan bu bilgilere bir şekilde
erişmek. Erişmek için önce bu bilgileri düzenlemek, düzenlenecek bilgileri de
önce tanımlamak gerekiyor.[11]
Yani, tanımlayamadığınız bilgi kaynaklarını düzenleyemezsiniz; bu kaynaklara
erişim sağlayamazsınız. Hızla artan ve kısa sürede ortadan kalkan elektronik
bilgi kaynaklarını nasıl tanımlayacak, düzenleyecek ve bu kaynaklara erişim
sağlayacaksınız? İşte sorun bu.
Daha önemli bir sorun
ise, kütüphanelerin sahip olduğu içeriğin, hızlı bilgi artışı, işleme gücü,
depolama vs. olanakları ile birleştirilip, bize esas yaptığımız işte yardımcı
olacak şekilde örgütlenmesidir. Bunu yapmadığımız zaman verileri alıp bir yerde
depolamanın çok bir esprisi yok. Bakın, taa 1930'larda H.G. Wells dünya ansiklopedisi diye bir kavramdan
söz etmişti.[12] Hatta
"dünya beyni"[13]
diye adlandırıyordu bunu; herkes oraya girdiğinde son bilgileri bulacak, vs. Öyle
bir şey söz konusu olmadı. Çünkü bilgi, bilim bu şekilde ilerlemiyor. Sonra,
bugün internet ile birlikte ortaya çıkan "Biz her şeyi depolayalım, nasıl
olsa buluruz" düşüncesi test edilmeye muhtaç. Biz henüz daha NASA
tarafından toplanan, uydulardan gelen verilerin %90'ını işleyememiş durumdayız.
Buyurun, teknoloji olanak veriyor diye her şeyi depolayın. Erişim olmadığı
zaman bundan ne kazanacağız?
Sorunun
fiziksel kısmı, yani makinelerle ilgili kısmı, erişimin doğrusal ve hantal
olmasından kaynaklanıyor. Anahtar sözcüğü veriyorsunuz, varsa var, yoksa yok.
Bunun benim size yukarıda özetlediğim bilgi erişim ikilemi ile hiçbir ilgisi
yok. Vatandaş bilgi ihtiyacının açıklayamıyorsa, zaten bu bilgi sistemlerinden
yararlanamıyor. Eğer zaten çok iyi açıklayabilecek durumdaysa, bilgi sistemine
ihtiyaç duyması gerekmiyor. Yani ben satır satır bildiğim dokümanı, neden
kalkıp da bilgi sisteminden tekrar bulmak isteyeyim ki.
Bilgi
işleme biçimi yönünden makinelerle insan beyni arasındaki -ki şu ana kadar da
çözemediğimiz kısım odur- fark da budur: İnsan beyninde gerek dizinleme gerek
erişim bağıntılı dizinleme dediğimiz "associative indexing" yoluyla
yapılıyor.[14] Yani, belki
iki doküman iki benzer kelime ile indekslenmemiş olabilir. Ama insan beyni çok
değişik bir şekilde bu ikisi arasında bir bağlantı kurabilir. Yani bilimsel
keşif vs. dediğimiz şey de bu. Belki de 2030 yıllarına kadar çözmeye
çalışacağımız sorun bu. İnsan beyninin bilgi erişim yöntemini taklit edebilir
miyiz? Yani değişik sorular var. Adınız ne derseniz, hemen söyleyebilirim. Ama
dün akşam ne yediniz derseniz, biraz düşünmem lazım. Ya da 15. yüzyılda acaba
Osmanlılar nasıl yaşadı derseniz, gidip kütüphanede bir hafta on gün araştırmam
lazım. Bu üç farklı tür bilgiye erişmek birbirinden çok farklı.
İnsan
beyni nasıl bir bilgi erişim sistemidir ki, belki 30 sene görmediğiniz bir
arkadaşınız size telefon açtığında, yüzünü bile görmemenize rağmen bir anda o
kişinin Ahmet ya da Ayşe olduğunu sesinden ayırdedebiliyor! Nasıl saklıyoruz o
bilgiyi? Nasıl erişiyoruz? Aynı şekilde, bazı kokular size bazı şeyler
hatırlatıyor. Ses ve koku gibi bilgiler kaydedilip bu bilgilere erişilebilir
mi? Beyin dışında kayıtlı bilgiler insanın düşünme ve sorun
çözme gücünün bir parçası haline getirilebilir mi?
Bu yönde çalışmalar devam ediyor.
Yani
bu konulardaki bilgi erişimle ilgili, yani beynin kapasitesini, yeteneklerini
eğer kurduğumuz bilgi işlem sistemlerine, bilgi erişim sistemlerine
yansıtabilirsek, herhalde o zaman esas çözümü bulmuş olacağız. Yoksa, diğerleri
daha çok geçici çözümler gibi gözüküyor. Tabii ki bu çözümleri aynı zamanda,
tıpkı şu anda beynin kendi edindiği bilgilerde uyguladığı gibi, sorun çözme
için kullanmak gerekli. Bugün sanal dünyalarda akıllı ajanlardan söz ediliyor.
Örneğin, benzetim (simülasyon) programıyla bir pilotu eğitiyorsunuz, orada bir
akıllı ajanınız var. Ama akıllı ajan önceden programlanmış değil; pilot yanlış
yaptığı anda uyarıyor. Sanal ortamlarda akıllı ajan kullanımı.. Acaba
böyle şeyler, bizim kataloglama,
depolama sorunlarımızı çözmek için de kullanılabilir mi?
Daha
da önemlisi biz hep bilgiyi dokunulamaz, görülemez, koklanamaz vs. olarak
biliyoruz. Acaba yakın gelecekte bilgiye dokunup, bilgiyi manipüle edebilecek,
şekillendirebilecek miyiz? Dolayısıyla, elle tutulabilir, gözle görülebilir
hale getirebilecek miyiz? Yani biraz önce Aydın Bey'in sözünü ettiği,
"bilişmek" fiilindeki o iş olurken, biz "onu"
gözleyebilecek miyiz? Size nöronlar arasındaki enerji değişiminin resminin
çekildiğini söyledim. Ama bilgi erişim sırasında ne oluyor, bunu henüz tam
olarak bilmiyoruz.
Teşekkür
ediyorum, sabrınız için.
©Yaşar Tonta
Son güncelleme: 10 Aralık 2001