Yaşar Tonta, Bilimsel Araştırmalarda İstatistik Tekniklerin Kullanımı ve Bulguların Sunumu Üzerine. Türk Kütüphaneciliği 13(2): 112-124, Haziran 1999. http://yunus.hacettepe.edu.tr/~tonta/yayinlar/istatistik.htm
Bilimsel Araştırmalarda İstatistik Tekniklerin Kullanımı ve Bulguların Sunumu Üzerine
On the Use of Statistical Techniques Used in Scientific Research and the Presentation of Findings
Bilimsel araştırmalarda değişkenler arasındaki ilişki düzeylerini belirleyebilmek amacıyla çeşitli tanımlayıcı istatistik teknikler yaygın olarak kullanılmaktadır. Veri toplamak için kullanılan ölçek türleri verilerin çözümlenmesinde kullanılacak istatistik teknikleri de belirlemektedir. Araştırma sonucu elde edilen bulguların anlamlı bir biçimde yorumlanması ve rapor halinde sunulması en az araştırmada kullanılan uygun istatistik teknikler kadar önemlidir. Niceliksel verilerin analizinde ve bulguların yorumlanmasında araştırmacıların en büyük desteği piyasada mevcut SPSS, SAS, STATISTICA gibi istatistik çözümleme yazılımlarıdır. Ancak hangi testlerin uygulanacağına ve hangi bulguların anlamlı ya da rapor edilmeye değer olduğuna sonuçta karar veren araştırmacıdır. Bu makalede istatistik tekniklerin kullanımı ve bulguların sunumu ile ilgili temel noktalara değinilmekte ve bazı önerilerde bulunulmaktadır.
Various descriptive statistical techniques are commonly used in scientific research to determine the degrees of relationship between variables. The types of measurements used to gather data also determine the types of statistical techniques that can be employed in the analysis of data. The interpretation and presentation of findings in a meaningful manner is as important as the statistical techniques used in the research. “Off-the-shelf” statistical software packages used in the analysis and interpretation of quantitative data such as SPSS, SAS and STATISTICA are the greatest support of the researcher. Yet it is the researcher who ultimately determines which tests would be run and which findings are meaningful and worth reporting. This paper touches upon some of the main points with regards to the use of statistical techniques and the presentation of results along with some recommendations.
Gerek fen gerekse sosyal bilimlerde bilimsel araştırmalarda elde edilen verilerin çözümlenmesinde ve bulguların yorumlanmasında çeşitli istatistik yöntemler yoğun olarak kullanılmaktadır. Disiplinlerarası bir sosyal bilim dalı olan kütüphanecilikte de araştırmalar sonucu elde edilen niceliksel (kantitatif) verilerin çözümlenmesinde ve yorumlanmasında çeşitli tanımlayıcı istatistik tekniklerden yararlanılmaktadır. Son yıllarda kütüphanecilik dalında yapılan araştırmalarda istatistik tekniklerin kullanımı giderek artmaktadır. Kuşkusuz bunda, eskiden çoğunlukla anabilgisayarlar ve minibilgisayarlar üzerinde çalışan SPSS (Statistical Package for Social Sciences) ve SAS (Statistical Analysis System) gibi istatistik çözümleme yazılımlarının artık kişisel bilgisayarlar üzerinde de çalışabilmesi ve söz konusu yazılımların kolayca edinilebilmesi de büyük rol oynamıştır.
Öte yandan, çoğu kişisel bilgisayarlarla birlikte gelen ve grafik kullanıcı arabirimi (Windows vb.) üzerinde çalışan Excel ve Lotus gibi tablolama (spreadsheet) yazılımları, kısıtlı ölçüde de olsa, istatistik çözümlemeler için de kullanılabilmektedir. Bu tür yazılımlar, değişkenler arasındaki ilişkilerin araştırılmasında ve verilerin yorumlanmasında olduğu kadar, tabloların hazırlanmasında ve grafiklerin çiziminde de kullanılmaktadır.
Kişisel bilgisayarlar üzerinde çalışan istatistik yazılım paketlerine kolayca erişilmesi araştırmacılar açısından kuşkusuz büyük bir avantajdır. Ancak bu tür yazılımların kullanılması sosyal bilimlerde yapılan araştırmaların kalitesini mutlaka arttırıcı bir etmen olarak da görülmemelidir. Yapısında kavramsal açıdan ya da izlenen araştırma yöntemi açısından eksiklikler bulunan bir araştırmada, elde edilen verilerin istatistik yazılımlar aracılığıyla çözümlenmesi ve yorumlanması çok fazla bir anlam ifade etmeyebilir.
Bu makalede, ölçme türlerinden kısaca söz edilmekte ve hangi tür ölçümlerle hangi istatistik tekniklerin kullanılabileceği üzerinde durulmaktadır. Bazı araştırmalarda yapılan hatalara değinilerek, araştırma raporlarında bulguların daha anlaşılabilir bir biçimde sunulabilmesi için çeşitli önerilerde bulunulmaktadır.
Kabaca tanımlamak gerekirse “değişken”, farklı değerler alabilen, farklı özelliklere sahip olabilen şeylerdir. Kişiler ve gruplarla ilgili değişkenler hakkında veri toplanabileceği gibi nesneler hakkındaki değişkenlerle ilgili bilgiler de toplanabilir. Örneğin, kütüphaneye gelen kullanıcıların cinsiyeti, en son bitirdikleri okul, ödünç aldıkları kitap sayısı, kütüphanede kalış süreleri vs. birer değişken olarak incelenebilir.
Değişkenlerle ilgili veri toplamada dört temel ölçekten yararlanılmaktadır:
Örneğin, kullanıcıların cinsiyetleri herhangi bir kuşkuya yer bırakmayacak şekilde “erkek” ya da “kadın” olarak ikili bir ölçme birimiyle (ölçekle) kolayca “sınıflandırılabilir”. Öte yandan, kullanıcıların kütüphaneden memnun olup olmadıklarını ölçmek istediğimizde ise daha farklı bir ölçek kullanma gereği duyar ve memnuniyet derecelerini, örneğin, “çok memnun”, “memnun”, “memnun değil”, “hiç memnun değil” gibi çoktan aza doğru “sıralayabiliriz”. Ya da, kullanıcıların kütüphaneden ödünç aldıkları kitap sayılarını birbirinden “eşit aralıklı” bir ölçek kullanarak saptayabiliriz: sıfır kitap, bir kitap, beş kitap ... gibi. Ancak burada beş kitap ödünç alan okuyucuların kütüphaneyi bir kitap ödünç alan okuyuculardan beş kat daha fazla kullandıklarını söylemek mümkün değildir. Veya hiç kitap ödünç almayan kullanıcıların kütüphaneyi hiç kullanmadıkları sonucuna varılamaz. Son olarak, kullanıcıların kütüphanede kalış sürelerini “oranlı” ölçek kullanarak ölçebiliriz: sıfır saat, bir saat, beş saat ... gibi. Dikkat edilecek olursa, kullanıcıların kütüphanede kalış sürelerini birbirleriyle orantılı olarak kesin bir şekilde söylemek mümkündür: kütüphanede dört saat harcayan bir kullanıcı iki saat harcayandan tamı tamına iki kat daha fazla zaman harcamıştır.
Bir araştırmada, araştırmanın amacına ve hakkında veri toplanan değişkenlerin özelliklerine göre bu ölçeklerden yerine göre biri, birkaçı veya hepsi kullanılabilir.1
Ölçek Türleri İle İstatistik Testler Arasındaki İlişkiler
Değişkenler hakkındaki verilerin hangi ölçek(ler) kullanılarak toplandığı bu değişkenlerle ilgili verilerin çözümlenmesinde ve yorumlanmasında kullanılacak istatistik testleri de belirlemektedir. Bir başka deyişle, bir değişkenin aldığı değerler özetlenirken, örneğin, ortalama ve standart sapmanın mı yoksa frekans dağılımı, ortanca veya tepedeğerin mi kullanılması gerektiği o değişken için hangi ölçek türüyle veri toplandığına bağlıdır. Ya da iki veya daha fazla değişken arasında ilişki olup olmadığı test edilirken kullanılacak anlamlılık (manidarlık) testinin türü (örneğin, t-testi, z-testi, c 2 [Ki-kare] testi), yine değişkenler için hangi ölçeklerle veri toplandığına bağlıdır.2
Nitekim belli başlı araştırma yöntemleri kitaplarından birisi olan Karasar’ın (1995) kitabında da bu konuya değinilmekte ve verilerin toplanmasında kullanılan ölçek türü ile istatistiksel çözümleme teknikleri arasındaki ilişkiler şöyle özetlenmektedir:
Peter Nardi, Babbie’nin (1998) kitabı için hazırladığı bir tabloda (Tablo 1) bağımlı ve bağımsız değişkenler hakkında veri toplamak için kullanılan ölçek türleri ile hangi istatistiksel testlerin kullanılabileceğini belirlemiştir.
Tablo 1. İlişki Ölçümleri ve Ölçek Düzeyleri
| Bağımsız değişken | ||||
| Sınıflama | Sıralama | Eşit Aralıklı/Oranlı | ||
| Sınıflama | Çapraz tablolar | Çapraz tablolar | ||
| Ki-kare | Ki-kare | |||
| Lambda | Lambda | |||
| Sıralama | Çapraz tablolar | Çapraz tablolar | ||
| Bağımlı | Ki-kare | Ki-kare | ||
| Değişken | Lambda | Lambda | ||
| Gamma | ||||
| Kendall's Tau | ||||
| Sommers' d | ||||
| Eşit Aralıklı- | Ortalamalar | Ortalamalar | Korelasyon | |
| Oranlı | t-testleri | t-testleri | Pearson's r | |
| ANOVA | ANOVA | Regresyon (R) | ||
Kaynak: Babbie, 1998: 415
Bu makalede yukarıdaki tabloda yer alan istatistiksel kavramlar ayrıntılı olarak tanımlanmayacaktır. Tablodan da görülebileceği gibi, verileri özetlemek için sınıflama ya da sıralama ölçek türleri kullanıldığı zaman çapraz tablolardan, eşit aralıklı ya da oranlı ölçek türleri kullanıldığı zaman ise ortalamalardan yararlanılmaktadır. Keza, değişkenler arasındaki ilişkileri test etmek için sınıflama ya da sıralama ölçek türleri kullanıldığı zaman Ki-kare testinden ya da Lambda, Gamma gibi dağılım katsayılarından, eşit aralıklı ya da oranlı ölçek türleri kullanıldığı zaman ise korelasyon ve regresyon katsayılarından yararlanılmaktadır. Babbie’nin (1998: 414) de not ettiği gibi, bağımlı ve bağımsız değişkenler hakkında farklı ölçekler kullanılarak veri toplandığında ilişki aramak için kullanılan teknikler biraz daha karmaşıklaşmaktadır. “Örneğin, bağımsız değişkenlerin sınıflama ya da sıralama ölçeği ile, bağımlı değişkenlerin ise eşit aralıklı ya da oranlı ölçekle ölçülmesi halinde, F ve t testleri uygulanabilir” (Karasar, 1995: 245).
İstatistik Çözümleme Yazılımları
Daha önce de değinildiği gibi, araştırmacılar SPSS vb. gibi istatistik yazılımlardan giderek daha sık olarak yararlanmaktadırlar. Araştırmacıya yardımcı araçlar olarak nitelendirilen bilgisayarlar ve istatistik yazılımlar şu amaçlarla kullanılmaktadır:
Çoğu zaman araştırmacılar, deneklerin anket ya da görüşme formlarında yer alan sorulara verdikleri yanıtları istatistik çözümleme yazılımlarına kodlayarak aktarmaktadırlar. Bunun temel nedenleri kodlu bilgilerin daha kolay işlenmesi ve tablo ve grafiklerde daha az yer kaplamasıdır. Bu bakımdan, anket formunda yer alan, örneğin, cinsiyet ile ilgili bir değişkenin alabileceği değerler “erkek” için "1", “kadın” için ise "2" olarak kodlanabilir.
Ancak kodlu bilgilerle kodlu olmayan bilgiler istatistik verilerin çözümlenmesi sırasında birbirleriyle karıştırılmamalıdır. Örneğin, bir sütunda kodlu bilgi olarak kütüphane kullanıcılarının cinsiyeti, diğerinde kodsuz bilgi olarak kullanıcıların ödünç aldıkları kitap sayısı bulunuyorsa, veriler özetlenirken çapraz tabloların mı yoksa ortalamanın mı kullanılması gerektiği hususuna dikkat edilmelidir. Bir başka deyişle, hem kodlu bilgi olduğu için, hem de veriler sınıflama ölçeği kullanılarak toplandığından ilk sütundaki bilgilerin ortalamasını almak pek bir anlam ifade etmeyecektir. Bunun yerine kullanıcıların cinsiyet dağılımını veren bir frekans tablosu çok daha anlamlı olacaktır. Öte yandan, ödünç alınan kitap sayısı kodsuz bilgi olduğundan ve veriler oranlı ölçek kullanılarak toplandığından verileri özetlemek için pekala ortalama ve standart sapmadan yararlanılabilir.
Araştırma Raporlarında İstatistik Tekniklerin Kullanımı ve Bulguların Sunumu
Ne yazık ki ölçek türleri ile ilgili hatalara akademik tezlerden üretilmiş araştırma makalelerinde bile zaman zaman rastlanabilmektedir. Üniversite kütüphanelerinde stratejik planlama konusunda yapılan bir çalışmada (Çalış, 1998) kütüphane yöneticilerine kullanıcı ihtiyaçlarının karşılanıp karşılanmadığı sorulmuş ve verilen yanıtlar aşağıdaki gibi tablolaştırılmıştır (Tablo 2, s. 208).
Cevap |
Sıklık |
Geçerli Yüzde |
Birikimli Yüzde |
|||
1,00 |
7 |
25,0 |
25,0 |
25,0 |
||
2,00 |
19 |
67,9 |
67,9 |
92,9 |
||
3,00 |
2 |
7,1 |
7,1 |
100,0 |
||
Toplam |
28 |
100,0 |
100,0 |
|||
Ortalama 1,821 |
Tablonun yorumlandığı metinden anlaşıldığı kadarıyla, "Cevap" sütununda verilen "1,00", "2,00" ve "3,00" rakamları araştırmada kullanılan anket formundaki "Kullanıcıların materyal isteklerini ne ölçüde karşılayabiliyorsunuz?" sorusuna verilebilecek "Tamamen karşılayabiliyoruz", "Kısmen karşılayabiliyoruz" ve "Hiç karşılayamıyoruz" şeklindeki yanıtların kodlanmış halidir.3 Kodlama işlemi verileri değerlendirmek amacıyla yapılmış ve bu iş için daha önce sözünü ettiğimiz SPSS yazılımının kişisel bilgisayarlar için hazırlanmış bir sürümü (versiyon) kullanılmıştır. İlgili araştırma raporunda da belirtildiği gibi, yedi üniversite kütüphanesi kullanıcıların isteklerini tamamen, 19'u ise kısmen karşılayabilmekte, ikisi ise hiç karşılayamamaktadır. Sunuş açısından "Cevap" sütununda bu seçeneklerin açık şekliyle verilmesi daha yararlı olabilirdi.
Yukarıdaki tabloda ilginç bir nokta daha göze çarpmaktadır: İlgili soruya verilen yanıtlar için aritmetik ortalama (1.821) verilmiştir. Daha açık bir anlatımla, sınıflama (nominal) ölçeği kullanılmasına ve verilen yanıtlar kodlanmasına karşın, her seçeneğin işaretlenme sıklığıyla ilgili seçeneğe karşılık gelen kodlu bilgi birbiriyle çarpılmış ve elde edilen rakam toplam yanıt sayısına bölünmüştür ((1,00 x 7) + (2,00 x 19) + (3,00 x 2) = 51/28 = 1.821). Elde edilen ortalama (1.821) kodlu bilgilerin ortalaması olduğundan okuyucu açısından pek fazla anlamlı değildir. (İlgili seçenekler sırasıyla "A", "B", "C" olarak da kodlanabilirdi.) Oysaki sınıflama ölçeği ile elde edilen veriler için tabloda verilen sıklıklar ve yüzdeler yeterlidir.
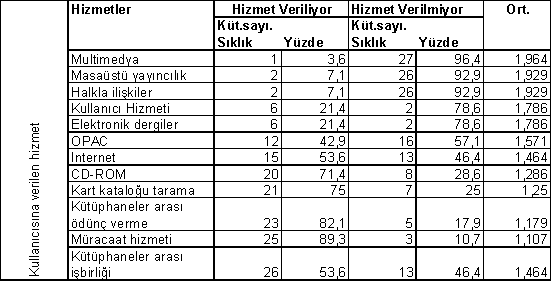
Aynı araştırmada üniversitelerde kullanıcılara verilen hizmetler de ayrı bir tablo halinde (Tablo 3, s. 209) aşağıdaki gibi düzenlenmiştir.
Dikkat edilecek olursa tabloda bazı gereksiz sütunlara yer verilmiştir. İlk sütun ("Kullanıcısına verilen hizmet") tabloya yeni bir bilgi eklememektedir. İkinci sütun ("Hizmetler") aynı işlevi görmektedir. Aynı şekilde 5. ve 6. sütunlardaki sıklık ve yüzde bilgileri 3. ve 4. sütunlardan kolayca çıkarılabilir. Bu soruya verilen toplam yanıt sayısı bilinmektedir (28). O halde, örneğin, Internet hizmeti 15 kütüphanede veriliyorsa geri kalan 13'ünde verilmiyor demektir. (Son satırdaki sıklık veya yüzde hatalıdır.) Son sütunda ("Ort.") ise yukarıda değindiğimiz hata yinelenmekte ve sınıflama ölçeği kullanılarak elde edilen kodlu bilgiler için ortalama verilmektedir.4
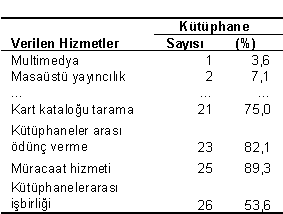
Herhangi bir bilgi kaybı olmaksızın söz konusu tablo aşağıdaki gibi düzenlenebilir. Tablodaki rakamlara daha fazla dikkat çekebilmek amacıyla gereksiz çizgiler (gridlines) çıkarılmıştır. Yer kazanmak amacıyla bazı satırlara yer verilmemiştir.
Tablo 3. Kullanıcıya Verilen Hizmetler (N=28)
Söz konusu çalışmada verilen bazı tablolarda ise ne yazık ki sütun ve satır başlıkları verilmemiştir. Kullanıcılara verilen CD-ROM hizmetleri ile “pazar payını artırmak ve rekabet avantajı sağlamak” arasında istatistiksel açıdan anlamlı bir ilişki olup olmadığının test edildiği Tablo 4 (s. 210) aşağıda verilmektedir:
| V188
(soru.30.7) V134 1(soru 18.3) 20 2,4000 1,046 ,234 V134 2 8 3,7500 1,282 ,453 |
| Anlam
farkı = -1,3500 Varyansların Eşitliği: F=1,160 P= ,291 t-testi için Anlamlılık Derecesi 95% Varyanslar t-değer df 2-T.S. |
| Eşit -2,90 26 ,008 ,466
(-2,308; -,392) Eşit olmayan -2,65 10,94 ,023 ,510 (-2,473; -,227) |
Bu tablodaki veriler CD-ROM hizmeti vermekle pazar payını artırmak ve rekabet avantajı sağlamak arasında “anlam farklılığı tespit edildiği” şeklinde yorumlanmaktadır (s. 209). Ancak bu haliyle yukarıdaki tabloyu yorumlamak oldukça zor gözükmektedir. Tablonun birinci kısmının ilk sütununda yer alan kodlu bilgiler muhtemelen anket formundaki ilgili sorulara ve bu sorulara karşılık gelen değişken numaralarına karşılık gelmektedir. Daha önce Tablo 3’te verilen rakamlardan “V134 1” ve “V134 2” ibarelerinin kütüphanenin CD-ROM hizmeti verip vermediği ile ilgili kodlar olduğu sonucuna varılabilir. Çünkü, herhangi bir başlık verilmemesine karşın, ikinci sütundaki rakamların (20 ve 28), sırasıyla, CD-ROM hizmeti veren ve vermeyen kütüphane sayılarına (“sıklık”) karşılık geldiği görülmektedir. “V188” ibaresinin “pazar payını artırmak ve rekabet avantajı sağlamak” değişkeninin kodu olduğu ise aynı çalışmada Tablo 23’te (s. 226) dolaylı olarak verilmektedir.
İkinci sütunda yer alan rakamların “sıklık” olduğunu daha önce belirtmiştik. Ancak diğer kolonlardaki rakamların ne anlama geldiğini temel istatistik kavramlar ve SPSS yazılımı konusunda bilgisi olmayanların çıkarmaları pek kolay değildir. Kaldı ki, tüm araştırma raporu okuyucularının bu kavramlar ve spesifik istatistik çözümleme yazılımları hakkında bilgili olmalarını beklemek pek gerçekçi de değildir. Dahası, araştırma raporlarında genellikle bu tür test sonuçları, daha sonra da değinileceği gibi, özet olarak verilebilir.
Üçüncü, 4. ve 5. kolonlardaki rakamlar CD-ROM hizmeti veren ve vermeyen kütüphaneler için, sırasıyla, “ortalama”, “standart sapma” ve “ortalama standart hata”yı vermektedir
Tablonun ikinci kesiminde verilen kavramlara da dikkat çekmekte yarar vardır. “Anlam farkı” olarak Türkçeleştirilen kavram aslında “ortalamaların farkı”dır (mean difference). "Mean" terimi "ortalama" anlamına gelmektedir. "t-testi için Anlamlılık Derecesi" ise "Ortalamaların Eşitliği için t-testi"dir.
Tablonun üçüncü kesiminde 1., 2. 3. ve 4. sütunlar için başlıklar verilmiş (sırasıyla, “Varyanslar”, “t-değer”, “df” ve “2-T.S.”), 5. ve 6. sütunlar için ise verilmemiştir. “df” “serbestlik derecesi”nin İngilizce kısaltmasıdır (degree of freedom). “2-T.S.” ise “İki yönlü anlamlılık” (2-tailed significance) teriminin kısaltmasıdır. Beşinci ve 6. sütunlardaki rakamlar ise, sırasıyla, “Farkların Standart Hatası” ve “Farkların %95 Güven Aralığı” anlamına gelmektedir.
Aynı çalışmada yer alan diğer bazı tablolar (bkz. 5-9, 11-12, 15-17) için de Tablo 4’te verilen şablon kullanılmıştır. SPSS yazılımı ile elde edilen ve bazı sütun başlıkları dışında doğrudan araştırma raporuna alınan bu tablolardaki rakamların da yukarıdaki gibi “okunması” gerekmektedir. Aslına bakılırsa, daha önce de vurgulandığı gibi, tabloda verilen t-testi sonuçları ile ilgili rakamlar tabloya gerek kalmadan da özetlenebilir. Ortalamalar arasındaki farkın istatistiksel açıdan anlamlı olup olmadığını test etmek için kullanılan t-testinde, iki grubun (yani, CD-ROM hizmeti veren kütüphaneler ile vermeyenler) pazar payını artırmak ve rekabet avantajı sağlamak ile ilgili yanıt yüzdeleriyle t ve p değerlerini vermek yeterlidir.5
Söz konusu çalışmada birçok değişken arasında anlamlı ilişkiler olup olmadığı t-testleriyle sınanmış ve sınama sonuçları Tablo 4’te verilen şablon kullanılarak ayrı ayrı tablolaştırılmıştır. Ancak çoğu değişken arasında istatistiksel açıdan anlamlı ilişkilere rastlanamamıştır. Değişkenler arasında ilişki bulunamamasının nedenleri konusunda herhangi bir yorum yapılmamıştır. t-testiyle sınanan ve aralarında istatistiksel açıdan anlamlı ilişki olmayan değişken çiftleri şunlardır:
Dikkat edilecek olursa, aralarında istatistiksel açıdan anlamlı ilişkiler olup olmadığı t-testi ile sınanan kavramlar son derecede “yüklü” kavramlardır. Örneğin, yukarıda Tablo 4’te ayrıntılı olarak verilen CD-ROM hizmeti vermekle pazar payını artırmak ve rekabet avantajı sağlamak arasındaki olası ilişkiyi ele alalım. “CD-ROM hizmeti”, “pazar payı”, rekabet avantajı” gibi kavramların nasıl tanımlandığı ve operasyonelleştirildiği açık değildir. Bu bakımdan, denekler araştırmacının bu kavramlar ile anlatmak istediklerinden farklı şeyler anlıyor olabilirler. Aynı şey "globalleşme akımı ve Internet", "bilgisayar teknolojisinin maliyetleri azaltabilmek için kullanılabilmesi ile Internet" ilişkileri ve diğer ilişkiler için de geçerlidir. Öte yandan, olası ilişkilerin sadece 28 deneğin yanıtlarına dayandığı gerçeği de gözden uzak tutulmamalıdır.
Araştırma verilerine göre, anketi yanıtlayan üniversite kütüphanelerinin %43’ünde stratejik planlama yapıldığı anlaşılmaktadır (s. 221). Araştırmanın ilgili kısmında üniversite kütüphanelerinde stratejik planlama yapılıp yapılmadığı hususu ile yöneticilerin stratejik planlama konusundaki bazı ifadelere (“çağdaş ve etkin kütüphane hizmeti verme”, “teknolojinin kütüphanelere etkisinin artması”, “kütüphanelerde de çağdaş yönetim tekniklerinin kullanılmasının sağladığı yararlar”) verdikleri yanıtlar arasında fark olup olmadığı hususunun c 2 (Ki-kare) testi ile sınandığı belirtilmektedir (s. 222). Ancak, verilen Ki-kare değerleri son derecede küçük olduğu halde (sırasıyla, 0,00306645, 0,000589106, 0,000765957), “...stratejik planlama yapılıp yapılmadığının sonucu ile...x2 testi sonucu bildirilen stratejik planlama ifadeleri arasında anlam farklılığı bulunmaktadır” (s. 222) yargısına varılmıştır. Oysaki verilen Ki-kare değerlerinin tümü standart Ki-kare tablosunda yer alan değerlerden çok daha küçüktür. Bir başka deyişle, stratejik planlama yapılan kütüphanelerdeki yöneticilerin söz konusu ifadelere verdikleri yanıtlarla, stratejik planlama yapılmayan kütüphane yöneticilerinin verdikleri yanıtların dağılımında küçük bir farklılık olmasına karşın, bu fark istatistiksel açıdan anlamlı gözükmemektedir. Farkın anlamlı olarak yorumlanması, raporda Ki-kare değerleri yerine yanlışlıkla p değerlerinin verildiğini düşündürmektedir. Çünkü, yukarıdaki satırların devamında (s. 222-223) Ki-kare testi uygulanan ve son derecede küçük Ki-kare değerleri elde edilen altı ilişki için de yukarıdakine benzer yorumlar yapılmıştır.
İstatistik teknikler niceliksel araştırmalar sonucu elde edilen verilerin özetlenmesinde ve değişkenler arasındaki olası ilişkilerin saptanmasında yaygın olarak kullanılmaktadır. Bu tekniklerden bazıları sıklık dağılımları, yüzdeler, ortalama, standart sapma, Ki-kare gibi tanımlayıcı istatistiklerdir. Öte yandan, kişisel bilgisayarlar üzerinde çalışan istatistik yazılımları niceliksel verilerin çözümlenmesinde ve yorumlanmasında araştırmacıların giderek vazgeçilmez yardımcıları haline gelmiştir.
Ancak, hernekadar istatistik yazılımları araştırmacıların yaygın olarak kullandıkları “araçlar” haline geldiyse de, araştırmalarda bilgisayar olanaklarından yararlanmak tek başına (bizatihi) kalite artırıcı bir öge olarak görülmemelidir. Bir araştırmanın mantıksal yapısının sağlam örülmesi, araştırma probleminin özenle kavramsallaştırılması, hakkında veri toplanacak değişkenlerle ilgili operasyonel tanımların dikkatle yapılması ve ölçek türlerinin belirlenmesi verilerin çözümlenmesinde bilgisayar kullanılmasından çok daha önemlidir. Çünkü, her tür kodlu ya da kodsuz sayısal veriler için istenen değerler (sıklık dağılımı, yüzdeler, ortalama, ortanca, standart sapma, korelasyon katsayısı, Ki-kare değeri, vd.) istatistik yazılım paketleri aracılığıyla kolayca hesaplanabilir. Ancak, bu değerleri yorumlayan bilgisayar değil, araştırmacıdır. Bu bakımdan, araştırmacı ne tür ilişkiler aradığını, bu ilişkilere temel oluşturacak verilerin hangi ölçek türü kullanılarak elde edilebileceğini, bulunan değerlerin ne anlama geldiğini mantık süzgecinden geçirmek zorundadır. Yoksa, istatistik yazılım paketleri ile hesaplanması kolay diye düşünülerek, ölçek türlerine dikkat edilmeden bulunacak değerler araştırmacıyı daha da zora sokabilir. Bir başka deyişle araştırmacı, elinde “balyoz” olduğunu düşünerek her şeyi “çivi” gibi görme yanılgısına düşmemelidir. Araştırma raporunu daha kolay anlaşılabilir kılmaya ve değişkenler arasındaki ilişkileri daha iyi yorumlamaya yarayan istatistik değerler, bilgisayar aracılığıyla hesaplanmış olsalar bile, yanlış kullanıldıkları zaman, okuyucunun araştırma raporunda tartışılan düşünceler üzerinde odaklaşmasını güçleştirecektir. Okuyucu büyük bir olasılıkla yapılan hatalar üzerinde kafa yormaya başlayacaktır.
Öte yandan, araştırma raporunun yazılması önemli ve zor bir iştir. Bulguların tablo ve şekiller yardımıyla anlaşılabilir bir biçimde sunulması okuyucunun işini son derecede kolaylaştıracaktır. Okuyucular çoğu zaman hem tabloyu, hem de tablonun yorumlandığı metni ayrı ayrı okumazlar. Ancak birbirinden bağımsız olarak okunsa bile, metin ve tablo kendi başlarına ayrı ayrı yeterince bilgilendirici olmalıdır. Tabloların gereksiz ayrıntılardan arındırılmış olmasına özen gösterilmeli, sütun ve satır başlıkları kolayca anlaşılabilir olmalıdır. Bu husus, araştırmada kullanılan anket formunun rapora eklenmediği durumlarda daha da fazla önem kazanır. Çünkü okuyucu tabloda verilen rakamların neyi ifade ettiğini anlamakta güçlük çekebilir.
Disiplinlerarası bir bilim dalı olan kütüphanecilikte niceliksel verilerin yorumlanmasında istatistik tekniklerin kullanılması, bulguların sunulması ve sonuç olarak daha iyi araştırma raporlarının yazılması ile ilgili önerilerimizi ise şöyle özetleyebiliriz.
Sonuç olarak; kütüphanecilik literatürünün kalitesinin bu tür çalışmalara ayrılan zaman ve harcanan emekle doğru orantılı olduğu gerçeği gözden uzak tutulmamalıdır.
Teşekkür
Bu çalışmanın ilk taslağını okuyarak önerilerde bulunan Doç. Dr. Aydın Erar’a teşekkür ederim.
Notlar
1. Ölçek türleri ile ilgili daha geniş bilgi için bkz.: Babbie, 1998: 141-143; Karasar, 1995: 143-146; Kaptan, 1995: 210-214; ve Sümbüloğlu ve Sümbüloğlu, 1998: 17-18.
2. Bu paragrafta geçen istatistik terimler için istatistik ya da araştırma yöntemleriyle ilgili temel ders kitaplarına bakılabilir (örneğin, Freeman, Pisani and Purves, 1980; Babbie, 1998: 404-433; Karasar, 1995: 206-246; Kaptan, 1995: 209-242; Aziz, 1994: 141-158; ve, Sümbüloğlu ve Sümbüloğlu, 1998: 11-18).
3. Anket formundaki ilgili soru burada verilen ile sözcüğü sözcüğüne aynı olmayabilir. Anket soruları makalede yer almamaktadır.
4. Aynı araştırmada Tablo 10, 13, 18, 19, 20, 21 ve 22'de de kodlu bilgiler için ortalamalar verilmiş ve, Tablo 2'de olduğu gibi, bazı tablolarda (19, 20 ve 22) kullanılan kodların karşılığı açıklanmamıştır.
5. Ancak araştırmada deneklerin pazar payını artırmak ve rekabet avantajı sağlamak hususundaki (ve diğer 25 husustaki) görüşleri sıralama (Likert) ölçeği kullanılarak elde edilmiş ve yanıtların ortalaması ve standart sapması verilmiştir (Çalış, 1998: 225-226, Tablo 23). Sıralama ölçeğiyle elde edilen veriler üzerinde sıklık dağılımları hazırlanabilir ve yüzdeleri hesaplanabilir. Ama "bu tür ölçümler üzerinde ortalama ve standart sapma gibi istatistikler...hesaplanamaz" (Kaptan, 1995: 212). Dolayısıyla, sınıflama (CD-ROM hizmeti verip vermeme) ve sıralama (pazar payını artırmak ve rekabet avantajı sağlamak) ölçeği kullanılarak elde edilen veriler için t-testinin kullanılmasının pek uygun olmadığı söylenebilir.
Aziz, Aysel. (1994). Araştırma yöntemleri - teknikleri ve iletişim. 2. bs. Ankara: Turhan.
Babbie, Earl. (1998). The practice of social research. 8th ed. Belmont, CA: Wadsworth.
Çalış, Asuman. (1998). “Üniversite kütüphanelerinde stratejik planlama: bir araştırma,” Türk Kütüphaneciliği 12(3): 201-230.
Freedman, David, Robert Pisani and Roger Purves. (1980). Statistics. New York: Norton.
Kaptan, Saim. (1995). Bilimsel araştırma ve istatistik teknikleri. 10. bs. Ankara: Rehber Yayınevi.
Karasar, Niyazi. (1995). Bilimsel araştırma yöntemi - kavramlar, ilkeler, teknikler. 7. bs. Ankara: 3A Araştırma, Eğitim, Danışmanlık Ltd.
Sümbüloğlu, Vildan ve Kadir Sümbüloğlu. (1998). Sağlık bilimlerinde araştırma yöntemleri. 2. bs. Ankara: Hatiboğlu Yayınları.